
REASONING MODES
ON / OFF / Low Effort + Budget
Toggle enable_thinking and low_effort live. Dial reasoning_budget to control thinking tokens.
STREAMING
Reasoning + Tool Calls
Watch green reasoning tokens stream, then orange incremental delta.tool_calls args build before the tool executes.
HARNESS FOCUS
Built for agents
The model is post-trained for long-horizon orchestration. This tiny harness makes the capabilities visible.
Screenshots from the app
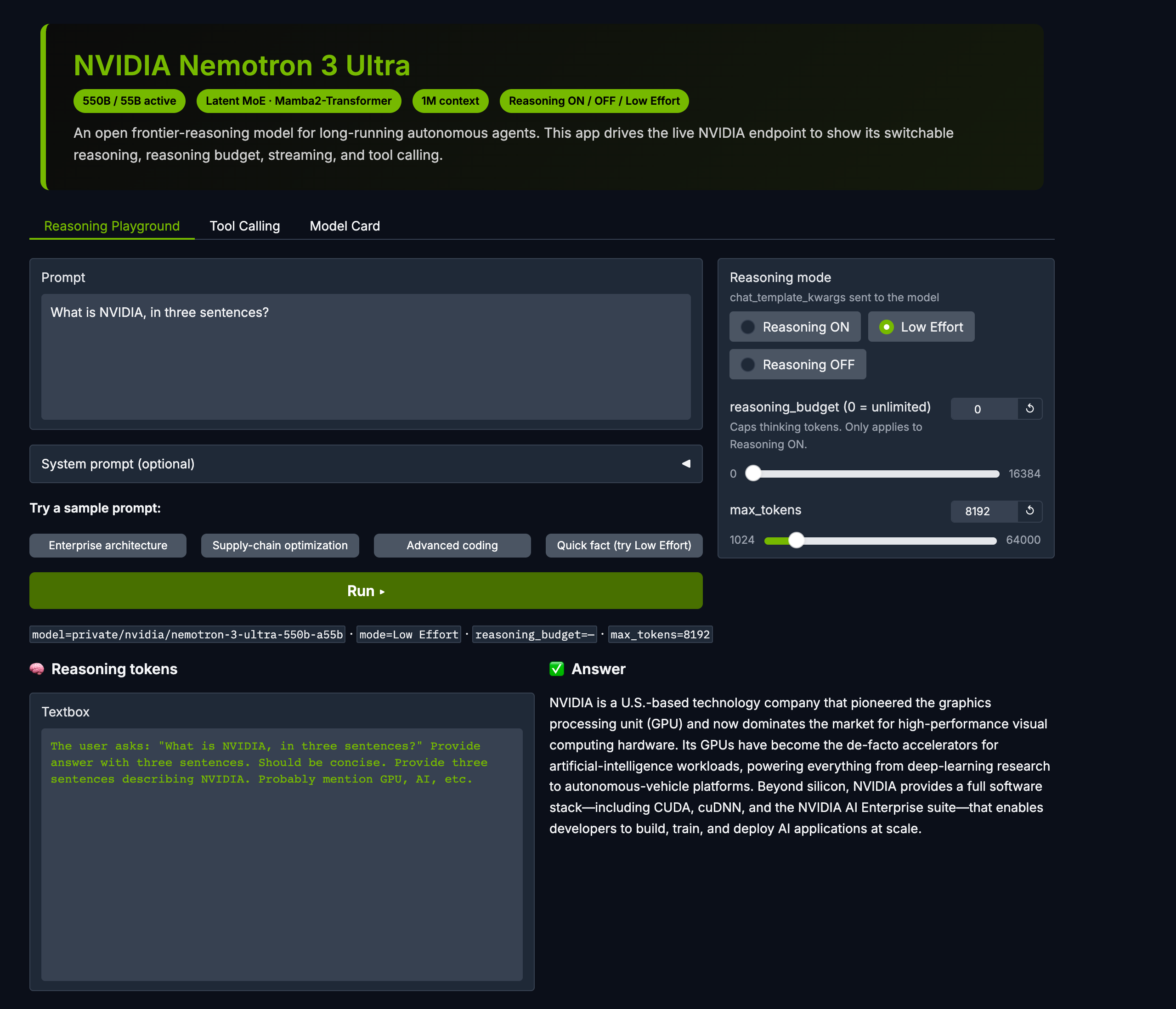
Reasoning playground — modes, budget, streaming
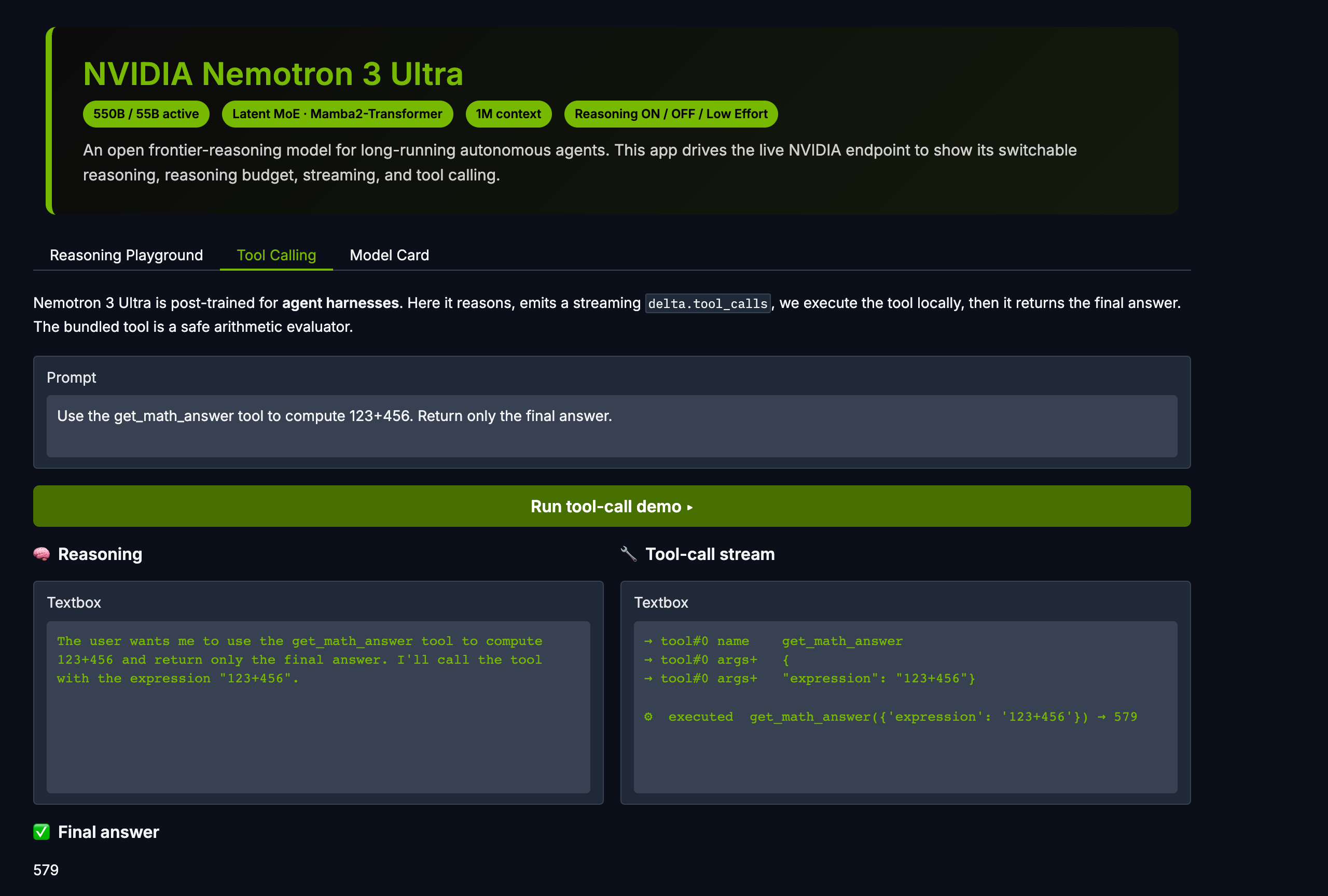
Streaming tool calls + local execution
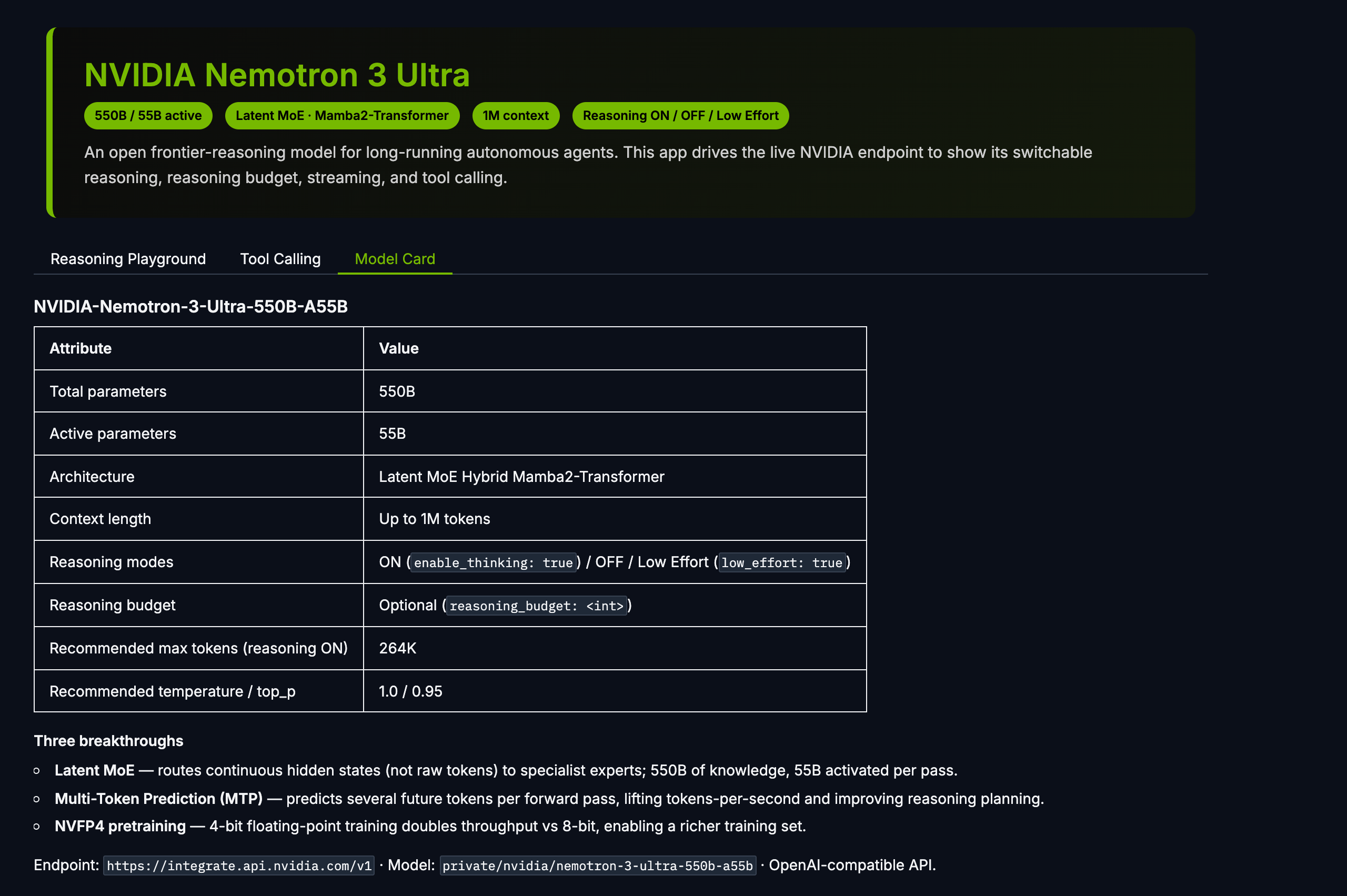
Model card + recommended settings
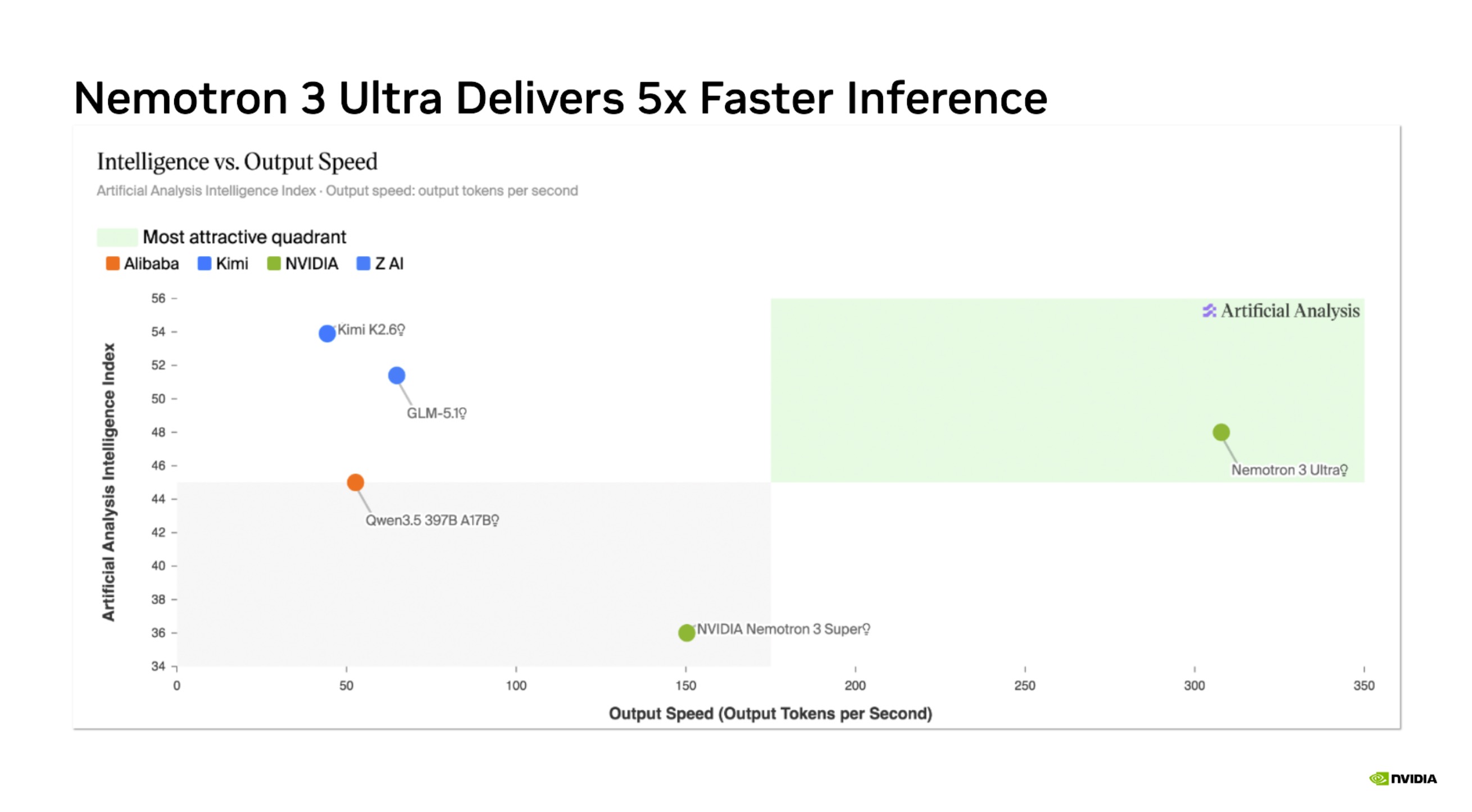
Intelligence vs output speed benchmark
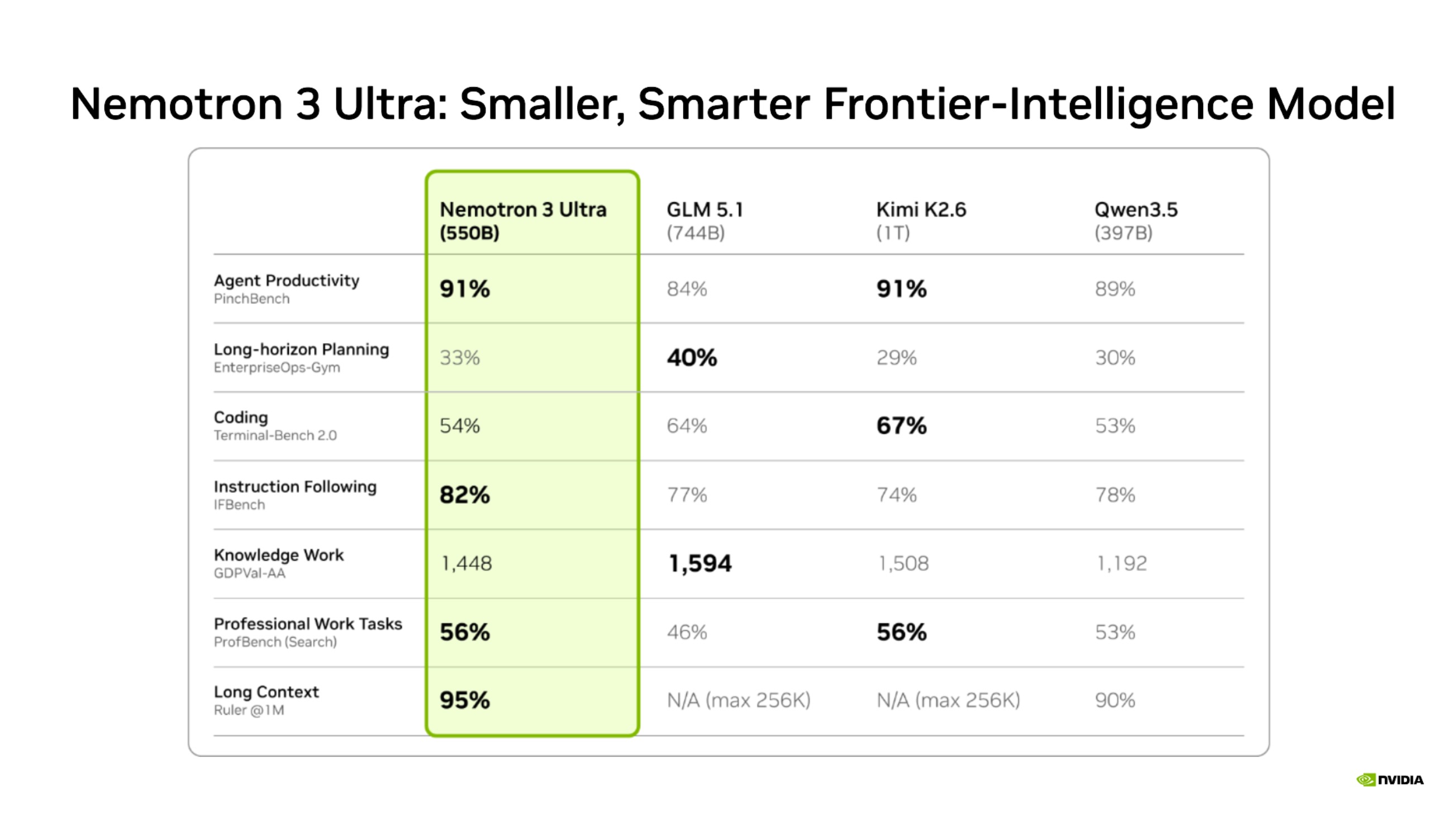
Benchmark comparison vs other models
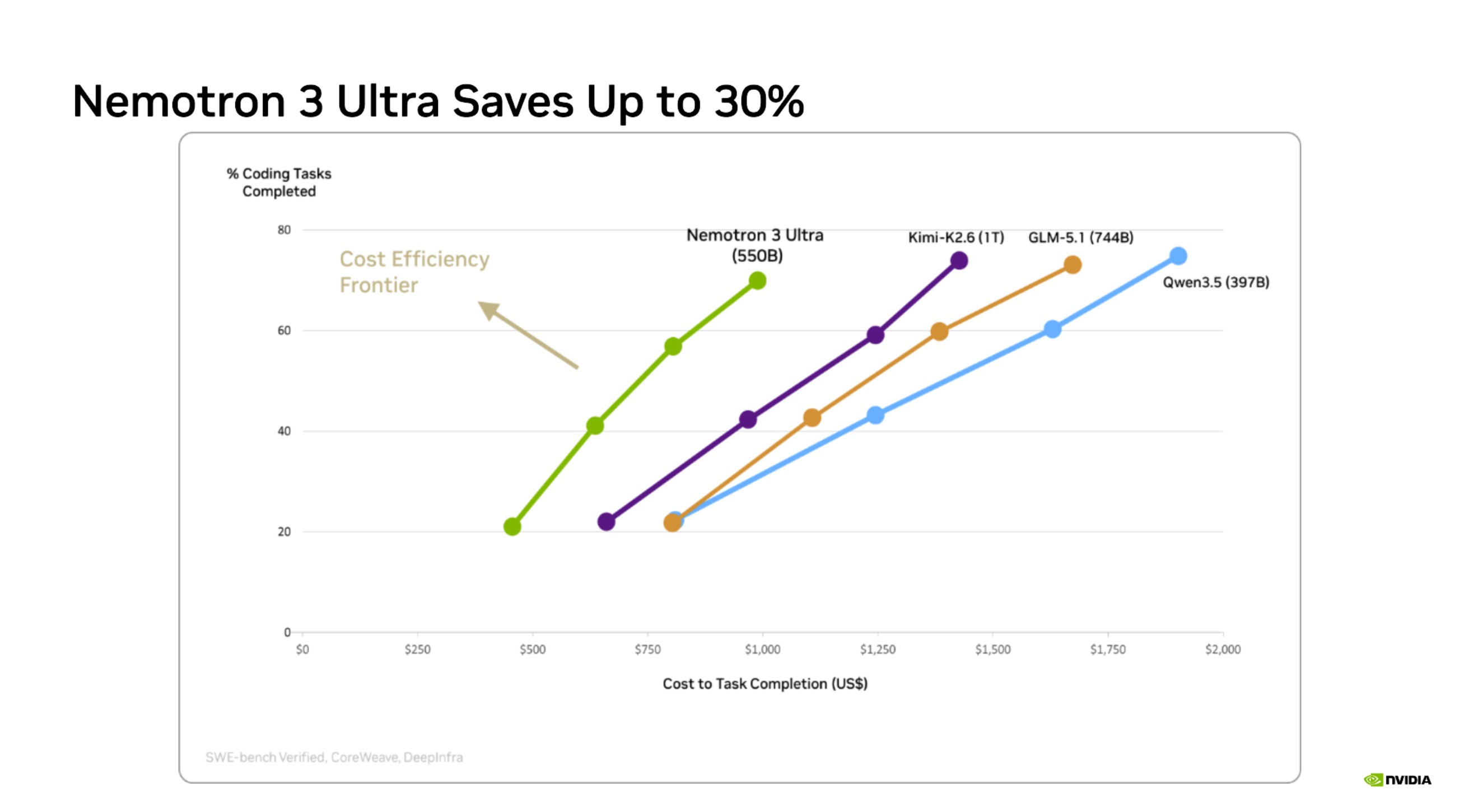
Cost efficiency frontier